Retrieval Augmented Generation (RAG)
What is RAG
RAG is a technique in natural language processing (NLP) that combines retrieval-based and generation-based methods.
- "reterival-based" means that, unlike purely generative models that create responses from scratch, retrieval-based systems rely on accessing existing data or knowledge to formulate their outputs
- it can be also seen as a special case of Intelligent Agent where the retriever is a tool the model can use
Why RAG is needed
- LLM faces challenges
- domain knowledge
- hallucinations
- training date cut off (outdated training set)
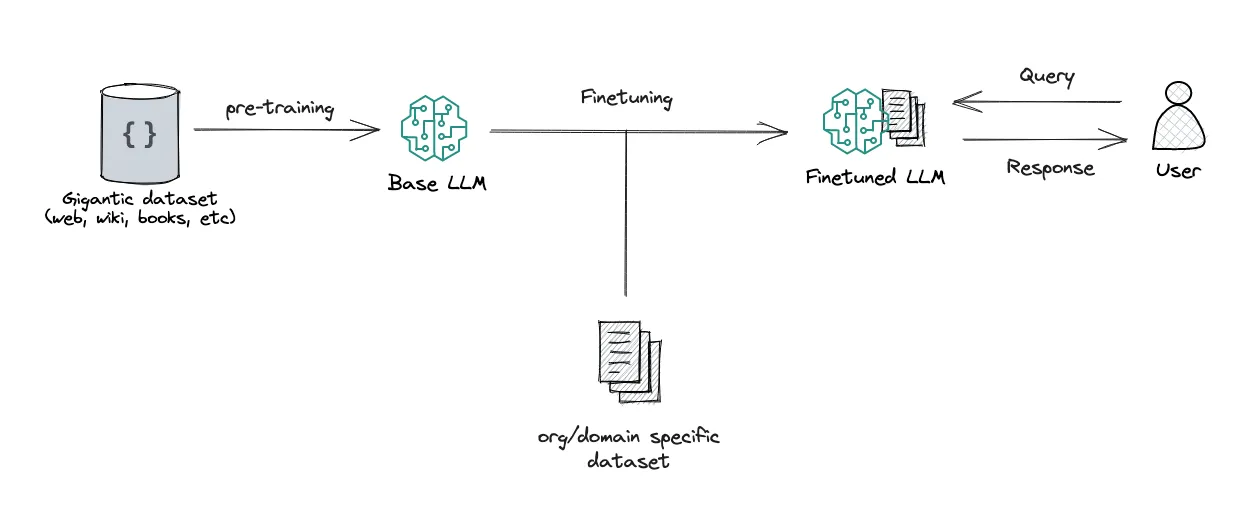
- These challenges maybe can be tackled by LLM Finetuning, but it's expensive to train the LLM
Data for RAG
RAG integrates with many types of data sources
- documents
- wikis
- expert systems
- web pages
- databases (tabular data)
- vector store (vector representation of text)
Data preparation for RAG
- data must fit inside context window
- data must be in format that allows its relevance to be assessed at inference time
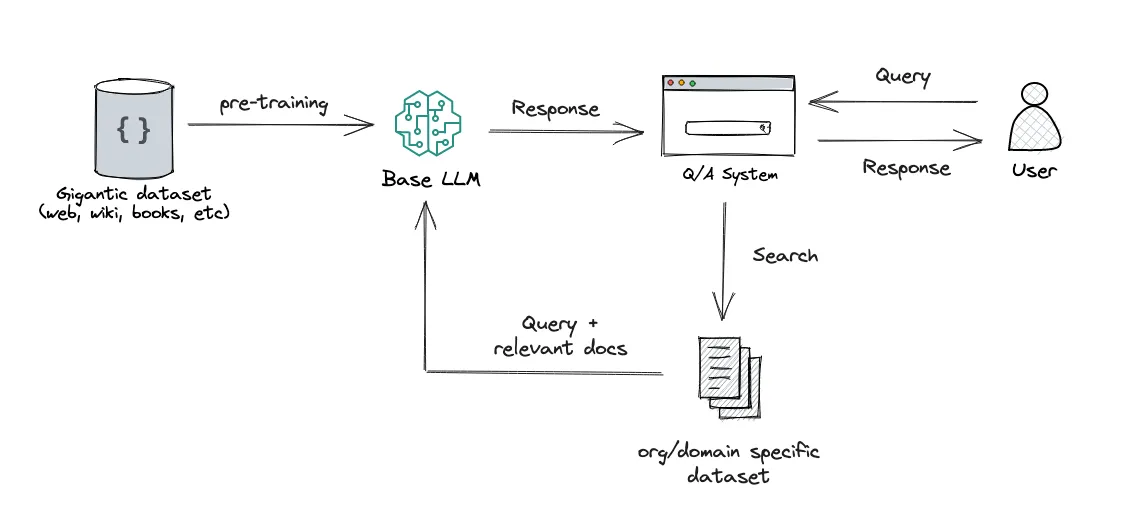
RAG Architecture
- generator that generates a response based on the retrieved information
- retriever that retrieves information from external memory sources, using two main functions
- indexing
- querying
Retrieval Algorithms
- key: ranking documents based on the relevance score to a given query
- common mechanisms
- term-based retrieval
- computes relevance at a lexical level
- TF-IDF algorithm
- TF = term frequency
- IDF = inverse document frequency - higher
- performance & cost: fast & less computationally
- embedding-based retrieval (=semantic retrieval)
- computes relevance at a semantic level
- contains an embedding model that, before querying, converts both data and query into embeddings using the same embedding model
- introduces vector databases and then runs vector search (e.g. searching with kNN similarity scores)
- performance & cost: can outperform term-based retrieval with finetuning
- hybrid search: combining term-based retrieval + embedding-based retrieval
- term-based retrieval
Retrieval Optimization
- chunking strategy
- reranking
- query rewriting (=query reformulation = query normalization)
- contextual retrieval