Recurrent Neural Networks (RNN)
Why recurrent
RNNs are called recurrent because they perform the same task for every element of a sequence, with the output being depended on the previous computations.
Another way to think about RNNs is that they have a “memory” which captures information about what has been calculated so far.
Architecture and components
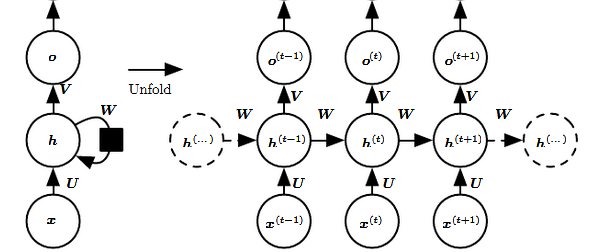
is the hidden state at time t is the input at time t , , and are weights for input-to-hidden connections, hidden-to-hidden recurrent connections, and hidden-to-output connections, respectively. - The function f is taken to be a non-linear transformation such as tanh, ReLU.
illustrates the output of the network and is also often subjected to non-linearity - recurrent: the output does not only depend on the input but also the hidden states
Forward propagation
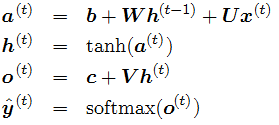
where the tanh can be ReLu too and the softmax can be sigmoid too.
Back propagation
The gradient computation involves performing a forward propagation pass moving left to right through the graph shown above followed by a backward propagation pass moving right to left through the graph.
Different types of RNN
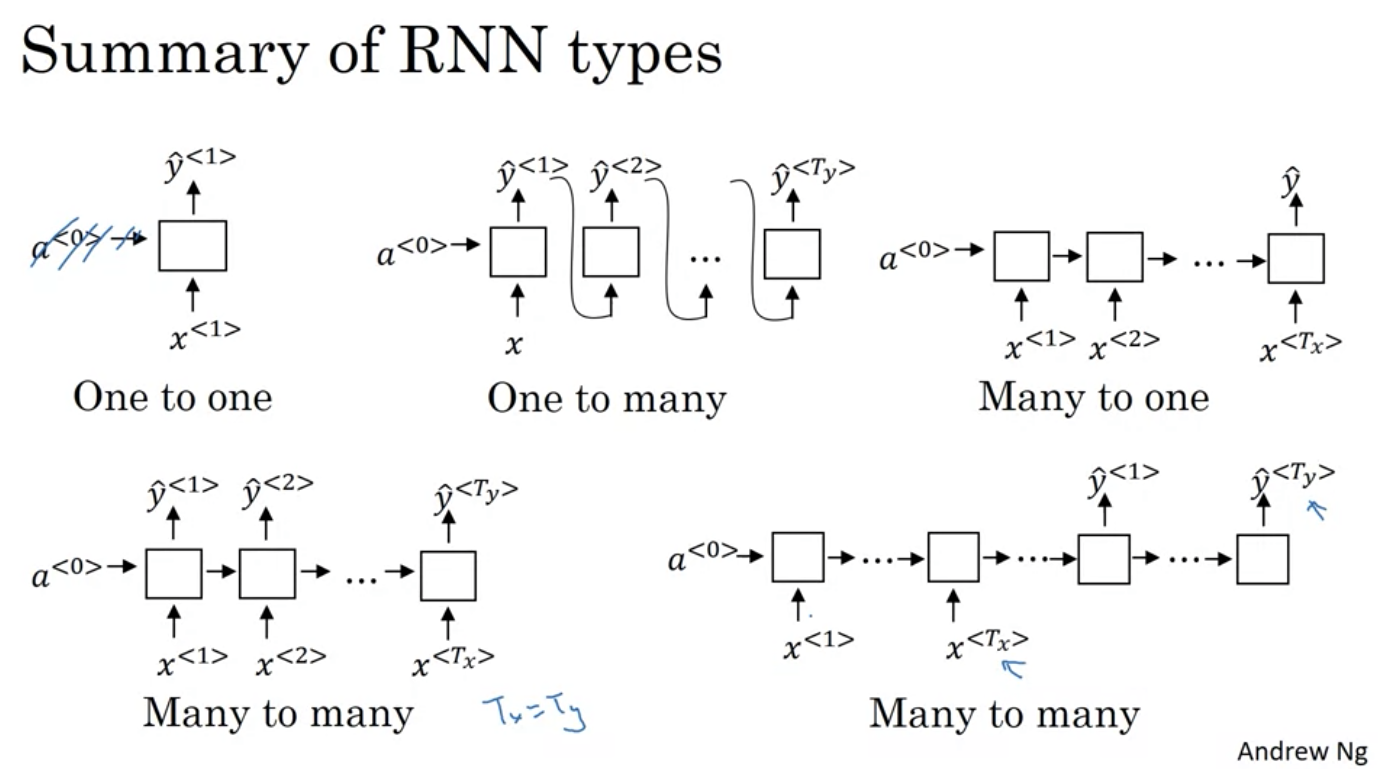
Variations of RNN
- Long Short Term Memory
- Grated Recurrent Unit
- Bidirectional RNN:
- a RNN that processes data in both forward and backward directions
- helpful in Natural Language Processing
- disadvantage: need the entire sequence of data before making any predictions
- Deep RNNs
- an extension of standard RNNs that consist of multiple layers of RNN units stacked on top of each other
- can learn complex representations
- computational complexity
Pros & Cons
- Pros: handle long-range dependency
- Cons: inefficient, gradient vanishing/exploding
- Transformer may work as a better alternative